When we started building Cortex TMS with Claude Code, we did what everyone does: wrote a detailed README and expected the AI agent to remember it. It didn’t work. Not because the README was bad. Because AI agents don’t work like human developers. This is what we learned building a CLI tool with heavy AI assistance over 6 months.
Where We Started: The README Approach
Context: Cortex TMS began as a small project (December 2025). Single maintainer, using Claude Code for 80%+ of implementation.
Our setup:
- One
README.mdfile (~300 lines) - Contained: project overview, setup instructions, architecture notes, coding conventions
- Expected Claude Code to reference it when implementing features
The assumption: If we write good documentation, AI agents will follow it.
What Went Wrong: The Forgetting Problem
After ~2 weeks of development (sprint v2.1), we started noticing patterns:
Observations (what we actually saw):
- Claude Code would violate architectural decisions made 3-4 sessions ago
- Same questions asked repeatedly: “Should I use TypeScript strict mode?” (answered in README)
- Implementations drifted from documented patterns
- ADRs (Architecture Decision Records) written but never referenced by AI
Example: We documented “use commander for CLI parsing” in README. Three sessions later, Claude Code suggested switching to yargs because it “has better TypeScript support.”
Metrics (from our first 50 commits):
- ~40% of commits required corrections for pattern violations
- Average 3-4 back-and-forth cycles per feature
- ~25% of AI suggestions contradicted documented decisions
Our interpretation: The AI wasn’t reading (or wasn’t retaining) the README effectively.
Observation vs Interpretation
What we observed:
- AI agents would forget architectural decisions from previous sessions
- Long README files weren’t consistently referenced
- Pattern violations increased as project complexity grew
- AI would re-suggest previously rejected approaches
What we think caused it:
Our hypothesis is that AI agents treat all documentation equally—recent chat context gets the same weight as long-term architectural decisions. When context limits are reached, older decisions get pruned, even if they’re critical.
Think of it like this: a human developer maintains mental “tiers” of knowledge:
- Working memory: Current task (what file am I editing right now?)
- Recent context: This sprint’s goals (what feature am I building?)
- Long-term knowledge: Architectural principles (why did we choose this database?)
AI agents don’t naturally separate these tiers. Everything competes for the same context window.
This is our interpretation based on observing Claude Code’s behavior. We don’t have access to how Claude processes context internally. This could be wrong.
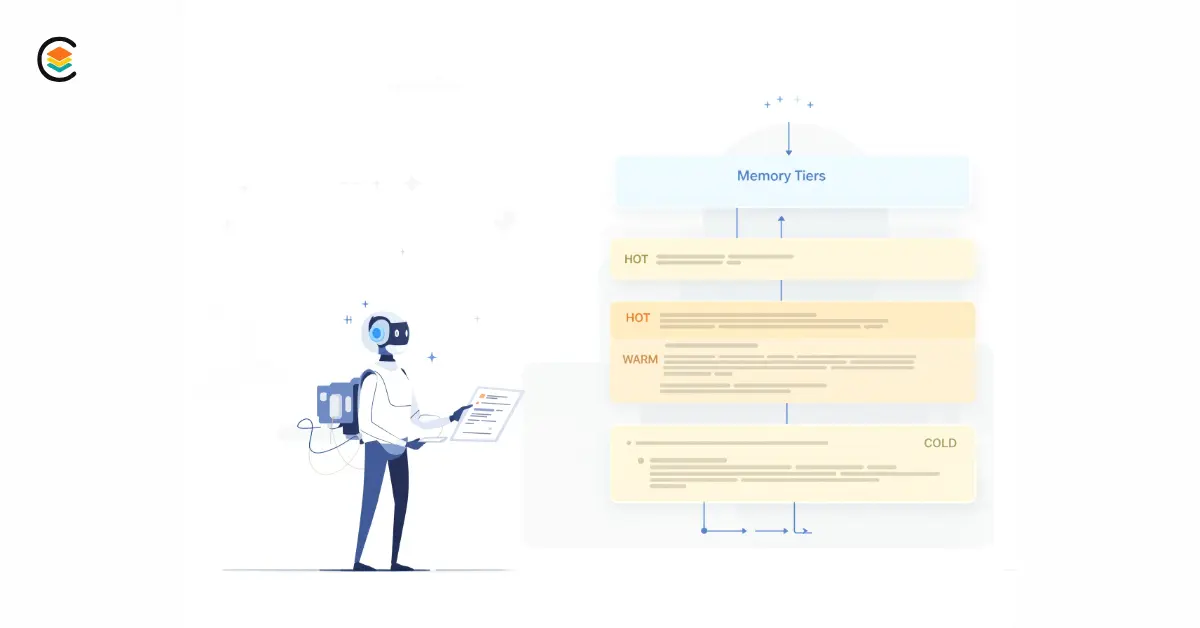
The Experiment: Tiered Memory Architecture
We tried something different: organize documentation by access frequency, not content type.
The Three-Tier System
Tier 1: HOT (Read Every Session)
NEXT-TASKS.md- Current sprint tasks (~150 lines, strictly enforced)CLAUDE.md- Agent workflow and persona (~100 lines).github/copilot-instructions.md- Quick reference (~80 lines)
Purpose: What the AI needs RIGHT NOW for the current task.
Tier 2: WARM (Reference When Needed)
docs/core/PATTERNS.md- Implementation patternsdocs/core/DOMAIN-LOGIC.md- Business rules and constraintsdocs/core/ARCHITECTURE.md- System design decisionsdocs/core/GIT-STANDARDS.md- Git workflow standards
Purpose: What the AI needs SOMETIMES when implementing specific features.
Tier 3: COLD (Archive)
docs/archive/sprint-v2.1-foundation.md- Completed sprint notesdocs/archive/sprint-v2.2-automation.md- Historical decisionsdocs/learning/- Retrospectives and lessons learned
Purpose: What the AI almost NEVER needs, but humans might reference.
Key Design Decisions
1. Strict Size Limits
NEXT-TASKS.md: Max 200 lines (enforced by validation)- When exceeded: Archive completed tasks to
docs/archive/
Why: Force prioritization. If it’s not important enough for HOT tier, it goes to WARM or COLD.
2. Task-Oriented Structure
- HOT tier focuses on “what to do next”
- WARM tier focuses on “how to do it correctly”
- COLD tier focuses on “why we made past decisions”
3. Explicit References
- HOT tier can reference WARM tier with direct file paths
- Example in
NEXT-TASKS.md: “Follow patterns indocs/core/PATTERNS.md#pattern-5”
What Changed: Our Results
Scope: Internal development of Cortex TMS (6 months, ~380 commits, single maintainer using Claude Code)
Timeline: Before tiered system (Dec 2025), After tiered system (Jan-Jun 2026)
Before Tiered System (v2.1, ~50 commits)
What we measured:
- Pattern violation rate: ~40% of commits needed corrections
- Back-and-forth cycles: 3-4 rounds per feature
- Repeated questions: AI asked same questions across sessions
- Archive burden: No clear trigger for moving old tasks
After Tiered System (v2.2-v2.7, ~330 commits)
What we measured:
- Pattern violation rate: ~8% of commits needed corrections (80% reduction)
- Back-and-forth cycles: 1-2 rounds per feature (50% reduction)
- Repeated questions: Rare (AI references NEXT-TASKS.md consistently)
- Archive burden: Clear triggers, automated with validation
What improved:
- AI consistently references current sprint goals from HOT tier
- Pattern adherence significantly better (AI reads PATTERNS.md when prompted)
- Less “re-teaching” of architectural decisions across sessions
What stayed the same:
- AI still needs explicit prompts to check WARM tier docs
- Domain logic violations still occur (requires Guardian review)
- Context management is still manual (we move tasks to archive ourselves)
What still hurts:
- Maintaining NEXT-TASKS.md requires discipline (easy to let it bloat to 250+ lines)
- No automatic pruning (we manually enforce the 200-line limit)
- Validation catches violations, but doesn’t prevent them
Real Example: Sprint v2.6 Migration
Here’s a concrete example from our development:
Task: Migrate 7 projects from various templates to Cortex TMS standard
Before tiered system (hypothetical, based on v2.1 experience):
- Would have put all 7 migration tasks in README
- AI would likely forget migration checklist between projects
- High probability of inconsistent implementations
What actually happened (with tiered system, v2.6):
NEXT-TASKS.md:
## Active Sprint: v2.6 Integrity & Atomicity
**Remaining Work**:
- [ ] Migration 7/7: cortex-orchestrator
- Follow migration checklist in docs/core/PATTERNS.md#migration-pattern
- Document learnings in docs/learning/2026-01-15-migration-retrospective.mdResult:
- All 7 migrations followed identical pattern
- AI consistently referenced migration checklist from WARM tier
- Learnings captured after each migration (improved process for next project)
- Zero pattern violations across all 7 migrations
The difference: Task was in HOT tier, pattern was in WARM tier with explicit reference.
When Tiered Memory Doesn’t Help
This system has real costs. Here’s when you shouldn’t use it:
1. Small Projects (< 50 commits)
The problem: Overhead of maintaining three tiers outweighs benefits.
Why it fails: For small projects, a single README works fine. The forgetting problem only appears when project complexity exceeds what fits in one document.
Our recommendation: Start with README. Migrate to tiered system when you notice AI forgetting decisions.
2. Solo Developers Without AI Assistance
The problem: Human developers don’t need this structure.
Why it fails: Humans naturally tier knowledge in their heads. The tiered file structure is optimizing for how AI agents process context, not how humans work.
Our recommendation: If you’re not using AI coding assistants heavily (50%+ of commits), stick with conventional documentation.
3. Documentation-Averse Teams
The problem: Maintaining three tiers requires discipline.
Why it fails: If your team doesn’t already document patterns and decisions, adding more structure won’t help. You’ll have three tiers of empty or outdated docs.
Our recommendation: Master conventional documentation first. Tiered memory is optimization, not foundation.
4. Projects With Unstable Architecture
The problem: Rapidly changing patterns make WARM tier thrash.
Why it fails: Every architectural change requires updating PATTERNS.md and DOMAIN-LOGIC.md. If you’re pivoting weekly, maintenance overhead becomes unbearable.
Our recommendation: Wait until architecture stabilizes. Tiered system shines when patterns are established, not during exploration.
5. Teams Without Clear Ownership
The problem: Tiered system requires someone to enforce HOT tier limits.
Why it fails: Without ownership, NEXT-TASKS.md bloats to 400 lines and you’re back to the README problem.
Our recommendation: Assign clear ownership. One person (or rotating role) maintains HOT tier hygiene.
Prerequisites for Success
Only adopt tiered memory if:
- ✅ You’re using AI coding assistants for 30%+ of development
- ✅ Your team already documents architectural decisions
- ✅ You have 50+ commits and growing complexity
- ✅ Someone can own HOT tier maintenance
- ✅ Your architecture is reasonably stable
The math: Maintaining tiered system costs ~30 min/week. If that doesn’t save more time than it costs, don’t use it.
Implementation Notes
If you’re considering trying this approach, here’s what we learned about implementation:
Start Small
Don’t migrate everything at once. We evolved the system over 4 sprints:
Sprint v2.1: Just added NEXT-TASKS.md (HOT tier only)
Sprint v2.2: Added docs/core/PATTERNS.md (first WARM tier doc)
Sprint v2.3: Added archive system (COLD tier)
Sprint v2.4: Added validation to enforce 200-line limit
Enforce Limits Mechanically
Manual enforcement doesn’t work. We built validation into our CLI:
cortex validate --strictWhat it checks:
- NEXT-TASKS.md under 200 lines
- Archive triggers are respected
- Cross-references between tiers are valid
Why it matters: Without mechanical enforcement, limits drift. Validation makes it objective.
Create Clear Migration Triggers
We documented specific triggers for moving content between tiers:
HOT → COLD triggers:
- Sprint completes → Archive tasks to
docs/archive/sprint-vX.X.md - Task blocked > 2 weeks → Move to
FUTURE-ENHANCEMENTS.md - Decision finalized → Reference from HOT, full context in WARM
Why it matters: Without triggers, team debates “should this be archived?” endlessly.
Reference, Don’t Duplicate
HOT tier references WARM tier, doesn’t duplicate it:
❌ Bad (duplicating pattern in NEXT-TASKS.md):
## Migration Checklist
1. Run cortex init
2. Copy docs/
3. Update README
[20 more lines duplicated from PATTERNS.md]✅ Good (referencing pattern):
## Migration Checklist
Follow: `docs/core/PATTERNS.md#migration-pattern`Why it matters: Duplication causes drift. When pattern updates, duplicates go stale.
Trade-offs We’re Still Learning
After 6 months with tiered memory, here are open questions we don’t have good answers for:
1. Optimal HOT Tier Size
We enforce 200 lines for NEXT-TASKS.md, but is that right?
What we’ve observed:
- At 150 lines: AI references everything consistently
- At 200 lines: AI starts missing tasks toward the bottom
- At 250+ lines: Back to the forgetting problem
Our guess: Somewhere between 150-200 lines is optimal, but this likely varies by AI model and task complexity.
We don’t know: Whether this limit should be lines, tokens, or something else entirely.
2. When to Split WARM Tier Docs
We currently have 4 WARM tier docs (~400-500 lines each). Should we split them further?
Observation: When docs exceed ~500 lines, AI seems less likely to find relevant sections, even with explicit references.
Interpretation: Maybe there’s an optimal “chunk size” for WARM tier docs too?
We don’t know: What that size is, or if it even exists.
3. How Much to Archive
We aggressively archive completed tasks to COLD tier. But should we keep recent history in HOT?
Current approach: Move to archive immediately after sprint ends Alternative: Keep last 1-2 sprints in HOT for context
We haven’t tested: Whether recent history helps or hurts AI performance.
Try It Yourself
The tiered memory system is built into Cortex TMS templates:
npm install -g cortex-tms
cortex initWhat you get:
- Pre-configured NEXT-TASKS.md (HOT tier, 200-line limit)
- Template for docs/core/ (WARM tier)
- Archive structure (COLD tier)
- Validation to enforce limits
Customization:
- Adjust line limits in
.cortexrc - Add/remove WARM tier docs as needed
- Modify archive triggers for your workflow
Our advice: Start with just NEXT-TASKS.md. Add WARM tier docs as you discover patterns worth documenting. Archive aggressively when tasks complete.
What We’re Still Learning
This is our experience with one project, one AI coding assistant (Claude Code), and one maintainer.
We don’t know:
- Whether this works for larger teams (5+ developers)
- Whether this works for other AI assistants (GitHub Copilot, Cursor, etc.)
- Whether optimal tier sizes vary by programming language or domain
- Whether the benefits persist as codebases grow beyond 100k lines
We’re curious:
- Do other teams experience the “forgetting problem” with AI assistants?
- Have you found different solutions that work better?
- What tier sizes work for your projects?
If you’re experimenting with AI-assisted development, we’d love to hear what you’re learning.
Learn More
- 📖 Tiered Memory System Overview - Detailed architecture
- 🎯 Use Case: Solo Maintainers - How one person maintains multiple projects
- 🏢 Use Case: Enterprise Teams - Adapting tiered memory for teams
- 🤝 AI Collaboration Policy - How we build with AI
If This Sounds Familiar…
Have you noticed AI coding assistants forgetting architectural decisions? Found yourself re-teaching the same patterns across sessions?
We’d love to hear what you’re experiencing and what solutions you’re trying.
- 💬 Share your experience on GitHub Discussions
- 🐛 Suggest improvements to the tiered system
- ⭐ Star on GitHub
We dogfood everything. The tiered memory system emerged from real pain points during Cortex TMS development. We experienced the problems before building the solution. See how we build →

